




Here in this blog, I will tell you why google has stopped using JSON and obviously it means REST API's too. You might be thinking, what is he saying, if not REST API's then what are they using now.I will surely write about it in another blog but before that you should know about protocol buffers. These days many projects have been shifted to ProtoBuf from JSON and many companies are using it for communication between their services.
I'm going through these points step by step to make it easy for you to understand and I will take example in Javascript as I love it.
Protocol Buffers and how will you create schema in proto file
protoc compiler and how to compile your proto file into output file of your chosen language
Why ProtoBuf not JSON
JSON and ProtoBuf example with code
If you only want to see the magic of ProtoBuf with practical example and how it is better than JSON check last section directly(Comparison of size and performance with example through code). I have created program both for JSON and ProtoBuf to compare the performance and size. You can check my github repo ProtoBuf to understand the code easily.
ProtoBuf and How to create schema in proto file
Google developed Protocol Buffers to use in their internal services. It is a binary encoding format that allows you to specify a schema for your data using a specification language, e.g.
We create a protocol buffers file with .proto extension.
In that first line should be syntax = "proto3" which tells us about which version of ProtoBuf we are using
syntax = "proto3";
message Employee {
int32 id = 1;
string name = 2;
float salary = 3;
}
It is an example of schema or message Employee where we define 3 fields and each field has type (how the data is encoded and sent over the wire), name (field name), number(it defines the order).
There are some reserved keywords(required, optional, repeated) and different data type there in protocol buffers you can learn more here
Taking an example to show you
message Employees {
repeated Employee employees = 1;
}
Here we are creating schema for array of employee and also custom type we are using of Employee type and we can create nested messages or schemas too.
How to compile proto file and language neutral behaviour
We understand how to create ProtoBuf format and file. Now how to use this in our code we will see.
ProtoBuf is language neutral what that exactly means I will try to explain.
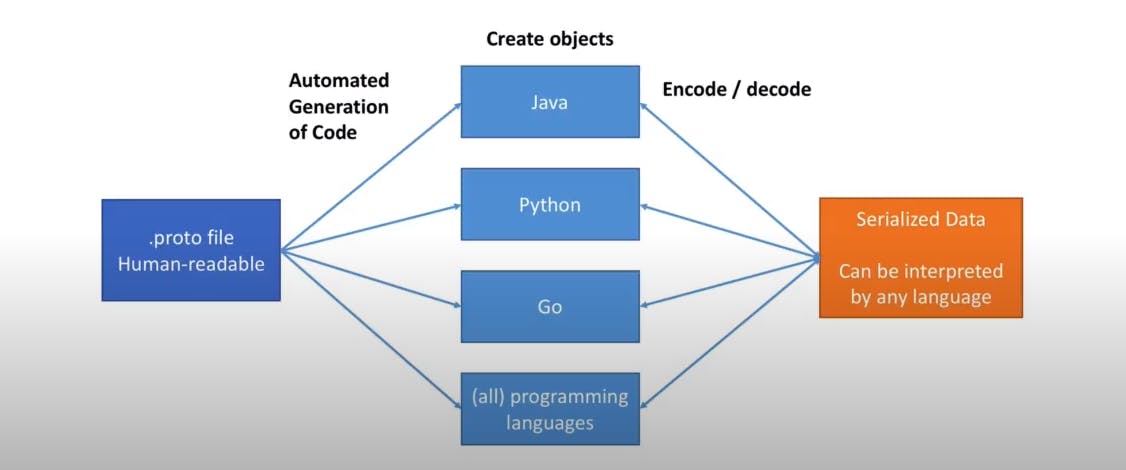
We will compile our proto file and for that we need 2 input, one our proto file and language of our choice to convert. According to that language it will create output file in the form of class objects and functions of that language. You can download compiler according to your OS from here
After that unzip it and inside it there will be bin/protoc.exe file which you have to run in case of Windows. Open cmd and run this command
pathToProtoC/bin/protoc --js_out=import_style=commonjs,binary:. filename.proto
Here I'm using --js_out=import_style=commonjs it will create objects in javascript and import style is telling the way to import proto file in javascript.
We will use these class objects to create our data format that we want in the JS file.
After that we change that data into serialized form to make it's size less and also that data can be deserialized by any language and it will be used in that, so language doesn't matter here.
Why Protocol Buffers not JSON
- Lesser in Size and Better in Performance and can be used for high volume services
Schema: Like in JSON you can send anything without checking whether it is a right property or not, but in ProtoBuf with schema you can keep a check on that part.
Backward Compatability for free: With numbered fields, you never have to change the behavior of code going forward to maintain backward compatibility with older versions. As the documentation states, once Protocol Buffers were introduced.
New fields could be easily introduced, and intermediate servers that didn’t need to inspect the data could simply parse it and pass through the data without the need to know about all the fields.
There are ways to update your proto file so that it will not affect the already created serialized file for decoding back.
Inside schema we can also add validation on field e.g. required keyword
If there is exchange of messages between two services rather than sending it to the browser because traffic will be higher for the services
Proto compiler will generate language specfic code that you input and you don't have to write any code for it.
Comparison of size and performance with example through code
Here download the source code from my repo ProtoBuf
I'm taking same data both in JSON and ProtoBuf format. After that writing that in one file and we will compare the size of these files.
Example for JSON
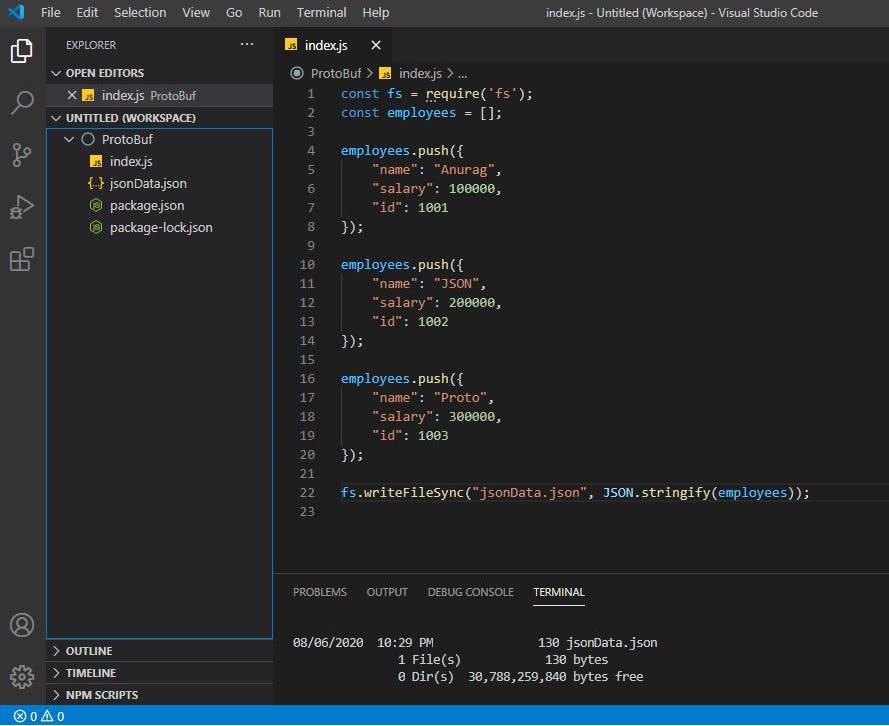
create file index.js
const fs = require('fs');
const employees = [];
employees.push({
"name": "Anurag",
"salary": 100000,
"id": 1001
});
employees.push({
"name": "JSON",
"salary": 200000,
"id": 1002
});
employees.push({
"name": "Proto",
"salary": 300000,
"id": 1003
});
fs.writeFileSync("jsonData.json", JSON.stringify(employees));
run this node index.js file
check size of file created using dir ./jsonData.json
Example for Proto File
create employees proto file employees.proto
syntax = "proto3";
message Employee {
int32 id = 1;
string name = 2;
float salary = 3;
}
message Employees {
repeated Employee employees = 1;
}
compile this using protoc compiler pathToProtoC/bin/protoc --js_out=import_style=commonjs,binary:. employees.proto
It will create output file employees_pb.js that we can used in our javascript
Install npm install google-protobuf
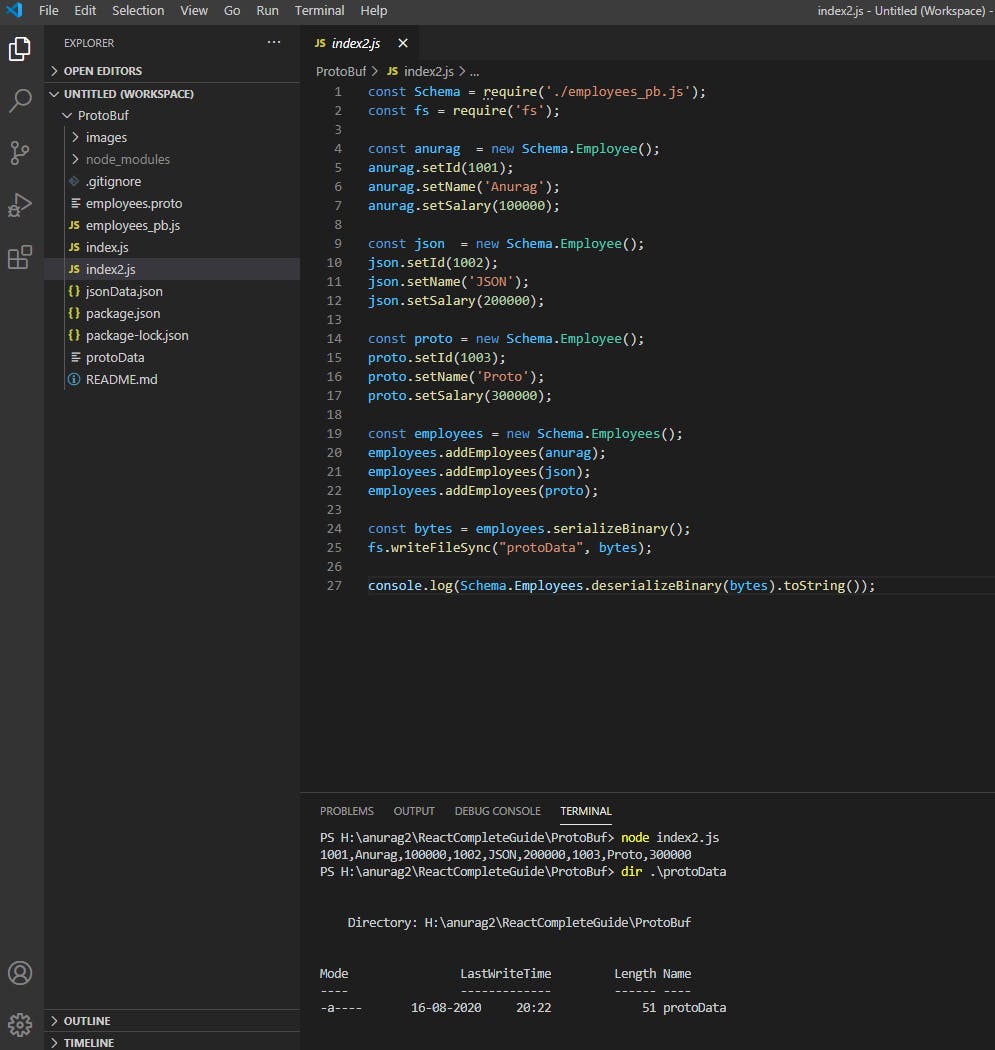
create file index2.js
const Schema = require('./employees_pb.js');
const fs = require('fs');
const anurag = new Schema.Employee();
anurag.setId(1001);
anurag.setName('Anurag');
anurag.setSalary(100000);
const json = new Schema.Employee();
json.setId(1002);
json.setName('JSON');
json.setSalary(200000);
const proto = new Schema.Employee();
proto.setId(1003);
proto.setName('Proto');
proto.setSalary(300000);
const employees = new Schema.Employees();
employees.addEmployees(anurag);
employees.addEmployees(json);
employees.addEmployees(proto);
const bytes = employees.serializeBinary();
fs.writeFileSync("protoData", bytes);
console.log(Schema.Employees.deserializeBinary(bytes).toString());
run this file node index2.js
check size of file created using dir ./protoData
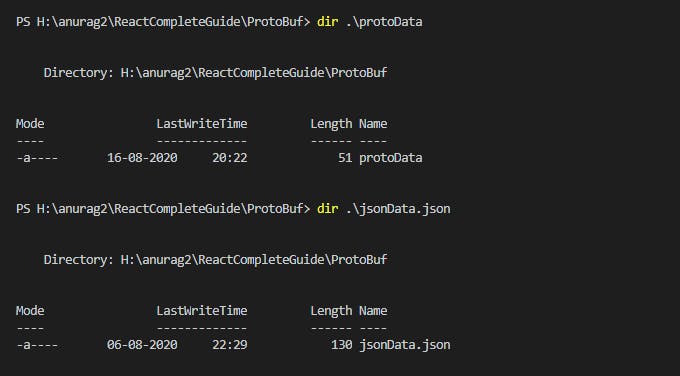
Difference in size and performance
Check the size of files created in JSON format and ProtoBuf binary format file and size of JSON file is more than double of ProtoBuf, so it means performance will be better if we are transmitting something in wire using ProtoBuf.
size of ProtoBuf file 51 bytes
size of JSON file 130 bytes
Thanks For Reading ...
If anything is wrong here by mistake do let me know. I will read it further and make changes accordingly.
Please like it if it helped you in anyway or comment if you have any doubts regarding this or want to give some suggestions.